L’importance des données propres pour la réussite de l’IA
Des données fiables pour des IA performantes
Données propres : Pourquoi des données propres sont la clé du succès de l’IA
Dans le domaine de l’intelligence artificielle (IA), les données constituent le fondement de tout modèle réussi. Cependant, toutes les données n’ont pas la même valeur. Pour que l’IA fournisse des prédictions précises, des informations fiables et des résultats significatifs, il est essentiel que les données soient propres. Sans données propres, les algorithmes d’IA risquent de produire des résultats faussés, conduisant à des conclusions erronées et à des erreurs potentiellement coûteuses. Dans cet article, nous verrons pourquoi des données propres sont essentielles au succès de l’IA, quels sont les risques d’une mauvaise qualité des données et quelles sont les meilleures pratiques pour maintenir des données propres.
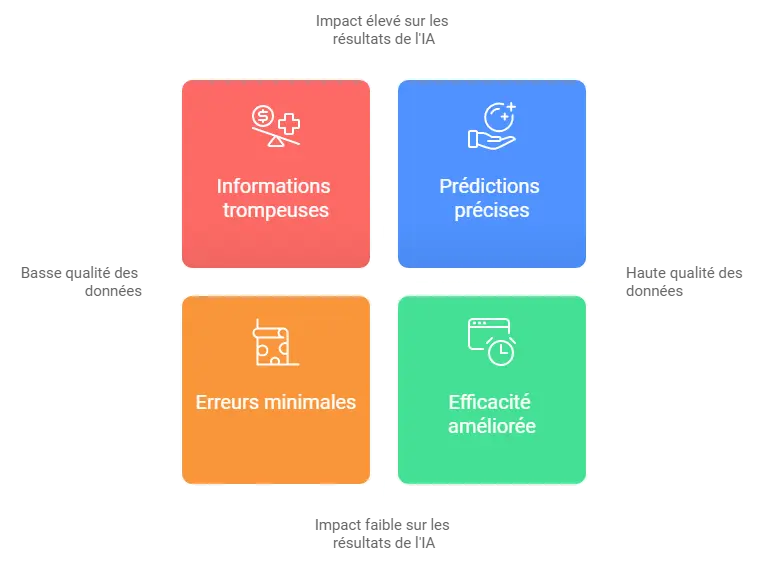
Table des matières
ToggleIntroduction : L’importance des données propres dans l’IA

Dans le domaine de l’IA et de l’apprentissage automatique (ML), les données sont essentielles. De la formation des modèles à la validation des algorithmes, la qualité des données détermine la réussite et la fiabilité globales d’un modèle d’IA. Des données inexactes, incomplètes ou biaisées perturbent non seulement les performances de l’IA, mais minent également la confiance des utilisateurs. En revanche, des données propres constituent une base solide pour construire des modèles d’IA robustes, précis et fiables qui ont un impact significatif. Pour les entreprises qui misent sur l’IA, investir dans la qualité des données peut faire la différence entre un succès à long terme et un gaspillage de ressources.
Qu'est-ce qu'une donnée propre ?
Les données propres sont des données exemptes d’erreurs, d’incohérences, de doublons et d’informations non pertinentes. Elles sont organisées, complètes, exactes et formatées de manière cohérente, ce qui les rend prêtes pour l’analyse et l’entraînement des modèles d’IA. Les données sales ou de mauvaise qualité, en revanche, contiennent des inexactitudes, des valeurs manquantes ou des valeurs aberrantes, ce qui peut compromettre considérablement les résultats de l’IA.
Les caractéristiques des données propres sont les suivantes
Les données propres ne se contentent pas d’améliorer l’IA ; elles constituent un facteur essentiel à chaque étape du pipeline de l’IA, de la formation initiale au déploiement final.
Les risques d’une mauvaise qualité des données dans l’IA
L’utilisation de données de mauvaise qualité dans les projets d’IA présente plusieurs risques importants :
Comment les données propres favorisent le succès de l’IA
Meilleures pratiques pour garantir la propreté des données dans les projets d’IA
Pour maintenir une qualité élevée des données dans les projets d’IA, il convient de suivre les meilleures pratiques suivantes :
Établir des lignes directrices claires concernant l'exactitude, l'exhaustivité et la cohérence des données avant leur collecte.
Utilisez des outils capables d'identifier et de rectifier les erreurs, les incohérences et les doublons en temps réel.
Effectuez régulièrement des contrôles de validation des données tout au long du cycle de vie des données afin de détecter les erreurs le plus tôt possible.
Créer des politiques pour superviser la gestion des données et assurer la conformité avec les normes de qualité des données.
Contrôler la qualité des ensembles de données au fil du temps, en particulier si la source de données ou le processus de collecte des données change.
Outils de nettoyage des données et de gestion de la qualité
| Outil | Fonction | Description |
|---|---|---|
| Trifacta | Nettoyage et transformation des données | Permet d'identifier et de corriger rapidement les incohérences |
| Talend Data Quality | Profilage et nettoyage des données | Offre un profilage, un nettoyage et une normalisation |
| OpenRefine | Nettoyage des données | Outil open-source pour traiter les données désordonnées |
| Déduplication | Déduplication des données | Bibliothèque Python pour la recherche de données dupliquées |
| DataRobot Paxata | Préparation et nettoyage des données | Outil piloté par l'IA qui prépare les données pour l'analyse |
Ces outils offrent des fonctionnalités robustes pour le profilage, le nettoyage et la préparation des données, garantissant que seules les données propres entrent dans le pipeline d’apprentissage de l’IA.
Un hôpital américain a mis en œuvre un modèle d'IA pour diagnostiquer des maladies à partir des données des patients. Après avoir constaté des prédictions incohérentes, il a procédé à un audit des données et découvert des lacunes et des incohérences dans l'ensemble des données. En investissant dans des outils de nettoyage des données et en normalisant les processus de collecte des données, l'hôpital a amélioré de 30 % la précision du diagnostic, soulignant ainsi la valeur des données propres dans les applications critiques.
Une institution financière a utilisé l'IA pour détecter les transactions frauduleuses, mais le modèle a d'abord eu des difficultés en raison de données sales avec des transactions mal étiquetées et des enregistrements en double. Après avoir
Des données propres sont la base de tout projet d'IA réussi. En s'assurant que les données sont exactes, cohérentes et pertinentes, les organisations peuvent développer des modèles d'IA fiables qui fournissent des informations significatives, des prédictions précises et des décisions fiables. Investir dans la qualité des données dès le départ s'avère payant en réduisant les biais, en améliorant l'efficacité et en permettant aux entreprises de prendre de meilleures décisions. Dans un monde où les données augmentent de façon exponentielle, la gestion des données propres continuera d'être l'épine dorsale du succès de l'IA.